بیایید همچنین توجه داشته باشیم که اگر یک سازنده به طور کامل همکاری نمی کند، نتیجه دیگری جز 1/2*a**-کردن آن وجود ندارد. پس انصافا اینجا mq و chronos تقصیری نداره . بنابراین از این نظر باید آن را نیز به 0.5*a** آماده کنم. 😂
CLBufferRead(tangents_handle,tangents,0,0,items);
اکنون باید محاسبات را در هسته به این صورت تبدیل کنیم: مقدار را دریافت کنید، مقدار دیوانهواری را روی آن محاسبه کنید، ارزش بدهید.
بسیار خوب، پس ما باید معیار تقسیم را پیدا کنیم، بیایید تعدادی اعدادی را که 512، 1024، 2048 و غیره دوست دارد بریزیم و نتایج را ثبت کنیم.
آیا می توانیم در اینجا به نتیجه ای برسیم؟ ارزش است:
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=1.8908 ... GLOBAL.ID[255]=255 : LOCAL.ID[255]=255 : GROUP.ID[255]=0 : T[255]=0.0147 GLOBAL.ID[256]=256 : LOCAL.ID[256]=0 : GROUP.ID[256]=1 : T[256]=-1.5271 ... GLOBAL.ID[511]=511 : LOCAL.ID[511]=255 : GROUP.ID[511]=1 : T[511]=2.3339 GLOBAL.ID[512]=512 : LOCAL.ID[512]=0 : GROUP.ID[512]=2 : T[512]=-0.8512 ... GLOBAL.ID[767]=767 : LOCAL.ID[767]=255 : GROUP.ID[767]=2 : T[767]=-0.1783
حالا اگر 11 هسته را اجرا کنم و 300 میلی ثانیه پیدا کنم، در مقابل اگر 170 میلی ثانیه پیدا کنم، چیزی درست به من می گوید.
حالا بیایید 257 مورد را پرتاب کنیم!
اگر این نشان دهد که 1024 گروه کاری می توانند به طور همزمان کار کنند چه می شود زیرا این دستگاه دارای 1024 واحد محاسباتی است؟
و ما مانده ایم که نارنجک را در دست گرفته ایم تا بفهمیم خوشه انگور است یا نه.
ما همه کارهای آماده سازی کسل کننده و آزاردهنده OpenCl را انجام می دهیم، نحوه اجرای برنامه، زمانی که فراخوانی می شود، زمینه های هسته را بافر می کند و یک پارامتر برای تعداد آیتم ها یا پرتقال هایی که باید برای آزمایش پرتاب شوند، ارائه می دهیم.
این کد به نظر می رسد:
این آزمایش یک فضای “کار” یک بعدی را با دستورات اصلی mql5 OpenCL در دسترس استقرار می دهد.
GLOBAL.ID[99]=99 : LOCAL.ID[99]=99 : GROUP.ID[99]=0 : T[99]=0.0905
ما باید بریدگی قابل توجهی را در زمان اجرا کشف کنیم که نشان میدهد هستهها در حال تعویض گروهها هستند، و برای پیچیدهتر کردن کارها، این باید همهکاره باشد، بنابراین اگر آن را اجرا کنید باید نشانهای دریافت کنید که در مقایسه با نشانههای من میتوانیم نتیجهگیری کنیم یا به آن نزدیک شویم. فعالیت در دستگاه
نه دستگاه من یا دستگاه شما، بلکه به طور کلی. (در صورت امکان)
بنابراین، چگونه می توانیم بگوییم که f* در حال وقوع است؟
#property version "1.00" int OnInit() { EventSetMillisecondTimer(33); return(INIT_SUCCEEDED); } void OnDeinit(const int reason) { } void OnTimer(){ EventKillTimer(); int ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); if(ctx!=INVALID_HANDLE){ string kernel="__kernel void memtests(__global int* global_id," "__global int* local_id," "__global int* group_id){" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}"; string errors=""; int prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); int ker=CLKernelCreate(prg,"memtests"); if(ker!=INVALID_HANDLE){ int items=2560; int global_ids[];ArrayResize(global_ids,items,0); ArrayFill(global_ids,0,items,0); int local_ids[];ArrayResize(local_ids,items,0); ArrayFill(local_ids,0,items,0); int group_ids[];ArrayResize(group_ids,items,0); ArrayFill(group_ids,0,items,0); int global_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int local_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int group_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); CLSetKernelArgMem(ker,0,global_id_handle); CLSetKernelArgMem(ker,1,local_id_handle); CLSetKernelArgMem(ker,2,group_id_handle); uint offsets[]={0}; uint works[]={items}; CLExecute(ker,1,offsets,works); while(CLExecutionStatus(ker)!=CL_COMPLETE){Sleep(10);} Print("Kernel finished"); CLBufferRead(global_id_handle,global_ids,0,0,items); CLBufferRead(local_id_handle,local_ids,0,0,items); CLBufferRead(group_id_handle,group_ids,0,0,items); int f=FileOpen("OCLlog.txt",FILE_WRITE|FILE_TXT); for(int i=0;i<items;i++){ FileWriteString(f,"GLOBAL.ID["+IntegerToString(i)+"]="+IntegerToString(global_ids[i])+" : LOCAL.ID["+IntegerToString(i)+"]="+IntegerToString(local_ids[i])+" : GROUP.ID["+IntegerToString(i)+"]="+IntegerToString(group_ids[i])+" "); } FileClose(f); int kernel_local_mem_size=CLGetInfoInteger(ker,CL_KERNEL_LOCAL_MEM_SIZE); int kernel_private_mem_size=CLGetInfoInteger(ker,CL_KERNEL_PRIVATE_MEM_SIZE); int kernel_work_group_size=CLGetInfoInteger(ker,CL_KERNEL_WORK_GROUP_SIZE); Print("Kernel local mem ("+kernel_local_mem_size+")"); Print("Kernel private mem ("+kernel_private_mem_size+")"); Print("Kernel work group size ("+kernel_work_group_size+")"); CLKernelFree(ker); CLBufferFree(global_id_handle); CLBufferFree(local_id_handle); CLBufferFree(group_id_handle); }else{Print("Cannot create kernel");} CLProgramFree(prg); }else{Alert(errors);} CLContextFree(ctx); } else{ Print("Cannot create ctx"); } } void OnTick() { }
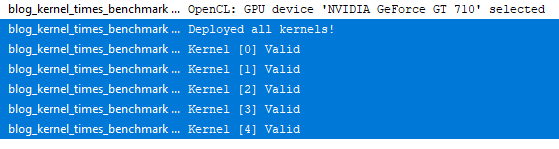
خوب بیایید آن را بنویسیم و همچنین اولین آزمایشی را انجام دهیم که 5 هسته را به طور همزمان و با داده های مختلف اجرا می کند!
حتی اگر 1 واحد محاسباتی را گزارش می دهد (این دستورات اطلاعاتی را نیز به آن اضافه می کنم تا بتوانید مقایسه کنید) و حتی اگر کیت ابزار cuda 192 هسته مختلف و 32 تاب را گزارش می دهد.
این فایل صادر شده است:
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=-0.7910 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=-0.7287 ... GLOBAL.ID[255]=255 : LOCAL.ID[255]=255 : GROUP.ID[255]=0 : T[255]=0.2203 GLOBAL.ID[256]=256 : LOCAL.ID[256]=0 : GROUP.ID[256]=1 : T[256]=1.4999 .. GLOBAL.ID[511]=511 : LOCAL.ID[511]=255 : GROUP.ID[511]=1 : T[511]=0.1762 GLOBAL.ID[512]=512 : LOCAL.ID[512]=0 : GROUP.ID[512]=2 : T[512]=-0.0072 ... GLOBAL.ID[767]=767 : LOCAL.ID[767]=255 : GROUP.ID[767]=2 : T[767]=-2.0688 GLOBAL.ID[768]=768 : LOCAL.ID[768]=0 : GROUP.ID[768]=3 : T[768]=-2.0622 ... GLOBAL.ID[1022]=1022 : LOCAL.ID[1022]=254 : GROUP.ID[1022]=3 : T[1022]=2.2044 GLOBAL.ID[1023]=1023 : LOCAL.ID[1023]=255 : GROUP.ID[1023]=3 : T[1023]=-0.6644
آیا ما به این موضوع اشتباه نزدیک شده ایم؟ آیا لازم نیست 1025 گروه کاری به صورت موازی اجرا شوند درست است؟
عالی . پس بیا بریم !
ابتدا بیایید یک آزمایش ساده ایجاد کنیم و امتحان کنیم و بسنجیم که GPU چه کاری انجام می دهد، یا اگر بخواهید، چگونه GPU حجم کار را بدون هیچ دستورالعملی تقسیم می کند.
int kernel_work_group_size=CLGetInfoInteger(ker,CL_KERNEL_WORK_GROUP_SIZE);
نه، هنوز یک گروه است، اگرچه gpu کمی تاخیر داشت.
و اگر این درست است، در مورد این مقدار در اینجا چطور؟
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 ... GLOBAL.ID[96]=96 : LOCAL.ID[96]=96 : GROUP.ID[96]=0 GLOBAL.ID[97]=97 : LOCAL.ID[97]=97 : GROUP.ID[97]=0 GLOBAL.ID[98]=98 : LOCAL.ID[98]=98 : GROUP.ID[98]=0 GLOBAL.ID[99]=99 : LOCAL.ID[99]=99 : GROUP.ID[99]=0
اجازه بدید ببینم . این یک فایل a** بزرگ است … اما خوشبختانه ما فقط به ردیف آخر نیاز داریم.
float tangents[];ArrayResize(tangents,items,0); float range=5.2; for(int i=0;i<ArraySize(tangents);i++){ float r=(((float)MathRand())/((float)32767.0)*range)-2.6; tangents[i]=r; }
بیایید فکر کنیم، چگونه می توانیم زمان لازم را اندازه گیری کنیم؟
درست ؟ من ممکن است اشتباه کنم
اینجا اولین چیزی است که کد می کنیم، آیا می توانیم چندین نمونه از یک هسته را اجرا کنیم؟ …
بنابراین از get_global_id(0) برای ذخیره همه شناسه ها استفاده می شود.
اجازه دهید کاری را که در اینجا انجام میدهیم تکرار کنم: میخواهیم تغییر «تغییر» را در عناصر پردازش «تصور کنیم»، یعنی لحظهای که واحدهای شلوغ تخلیه میشوند و دادههای جدید را به طور مؤثر دریافت میکنند، یا من فکر میکنم که تعداد پردازشها را به ما میدهد. عناصر (من حدس می زنم برابر باشد
پس بیایید با پرتاب 100 مورد شروع کنیم.
خوب ما 1025 گروه کاری دریافت می کنیم … باشه
CL_DEVICE_MAX_WORK_GROUP_SIZE
بنابراین ما یک نشانگر شناور جهانی به آرگومان های هسته اضافه می کنیم
بنابراین اگر “معیار” خود تکرارهای بهینه را پیدا کند، تا زمانی که تکرارهایی که ارسال میکند در “زمانهایی” بزرگتر از بازه زمانی باشد، وارد یک حلقه میشود.
بله، ما همچنین می توانیم اندازه 0 را ارسال کنیم و با افست بازی کنیم تا از کش gpu جلوگیری کنیم.
aaand (من 2 ساعت را در اینجا تلف کردم زیرا فراموش کردم بافر را دوباره بخوانم 🤣) بنابراین، فراموش نکنید که وقتی دادهها را میخواهید، بافر خواندن را فراخوانی کنید.
اگر 10 هسته را به طور همزمان برای اجرا ارسال کنم، به طور کلی 150 میلی ثانیه زمان اجرا دریافت می کنم، به این معنی که حداقل زمان ثبت شده من در آیتم های اطلاعات هسته که از حداکثر زمان ثبت شده کم می شود، 150 میلی ثانیه خواهد بود.
__global float* _tangent,
سپس زمان ها را خروجی می گیریم و تصمیم می گیریم که چگونه از آنجا ادامه دهیم
ما باید زمان اجرا را اندازه گیری کنیم، اما چه؟
خب بیایید بفهمیم
بنابراین میتوانیم از این شاخصها استفاده کنیم و اگر تعدادی از کارها را روی GPU بریزیم، ببینیم که گروهها چگونه مرتب شدهاند.
مقدار هسته ها را به خارج از بلوک های if منتقل می کنیم، 2 تایمر را در شروع و پایان ضربه می زنیم و تفاوت را چاپ می کنیم:
GLOBAL.ID[99]=99 : LOCAL.ID[99]=99 : GROUP.ID[99]=0 : T[99]=-2.4797
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=1.5756 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=-1.1957 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : T[2]=0.6411 … GLOBAL.ID[198]=198 : LOCAL.ID[198]=198 : GROUP.ID[198]=0 : T[198]=0.5839 GLOBAL.ID[199]=199 : LOCAL.ID[199]=199 : GROUP.ID[199]=0 : T[199]=-1.5742
عالی، حالا 50 هسته را با بار مرده (بدون کش) انجام دهید
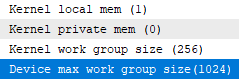
1024 : آها الان به 4 گروه تقسیم شد ! بنابراین حداکثر اندازه گروه برای این دستگاه 256 مورد است؟
اگر بخواهیم 1025 گروه کاری (برای این دستگاه) بگیریم، به 1025*256 آیتم نیاز داریم، یعنی 262400 مورد.
class kernel_info{ public: int offset; int handle; ulong start_microSeconds; ulong end_microSeconds; kernel_info(void){reset();} ~kernel_info(void){reset();} void reset(){ offset=-1; handle=INVALID_HANDLE; start_microSeconds=0; end_microSeconds=0; } void setup(int _hndl,ulong _start,int _offset){ handle=_hndl; start_microSeconds=_start; offset=_offset; } void stop(ulong _end){ end_microSeconds=_end; } }; kernel_info KERNELS[]; int OnInit() { EventSetMillisecondTimer(33); return(INIT_SUCCEEDED); } void OnDeinit(const int reason) { } void OnTimer(){ EventKillTimer(); int ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); if(ctx!=INVALID_HANDLE){ string kernel="__kernel void bench(__global int* global_id," "__global int* local_id," "__global int* group_id," "__global float* _tangent," "int iterations){" "float sum=(float)0.0;" "float of=(float)_tangent[get_global_id(0)];" "for(int i=0;i<iterations;i++){" "sum+=((float)tanh(of-sum))/((float)iterations);" "}" "sum=(float)0.12345;" "_tangent[get_global_id(0)]=0.123;" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}"; string errors=""; int prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); int kernels_to_deploy=5; int iterations=1000; ArrayResize(KERNELS,kernels_to_deploy,0); bool deployed=true; for(int i=0;i<kernels_to_deploy;i++){ KERNELS[i].handle=CLKernelCreate(prg,"bench"); if(KERNELS[i].handle==INVALID_HANDLE){deployed=false;} } if(deployed){ Print("Deployed all kernels!"); for(int i=0;i<kernels_to_deploy;i++){ if(KERNELS[i].handle!=INVALID_HANDLE){Print("Kernel ["+i+"] Valid");} else{Print("Kernel ["+i+"] InValid");} } }else{ Print("Cannot deploy all kernels!"); for(int i=0;i<kernels_to_deploy;i++){ if(KERNELS[i].handle!=INVALID_HANDLE){Print("Kernel ["+i+"] Valid");} else{Print("Kernel ["+i+"] InValid");} } } for(int i=0;i<kernels_to_deploy;i++){ if(KERNELS[i].handle!=INVALID_HANDLE){ CLKernelFree(KERNELS[i].handle); } } CLProgramFree(prg); }else{Alert(errors);} CLContextFree(ctx); } else{ Print("Cannot create ctx"); } }
جالب است، اکنون باید با ارائه یک عدد تکرار به عنوان آرگومان، کار را کمی دشوارتر کنیم.
این محاسبه tanh را حلقه می کند و برای هر نتیجه ما tanh شناور / تکرار مماس را جمع می کنیم.
مرتب
در واقع اجازه دهید آن را در کد اضافه کنم و ببینم چه چیزی را برمی گرداند:
خروجی فایل به این شکل است (در بالا) و می بینید که به هیچ وجه بار کار را تقسیم نکرده است.
وظیفه کشف نحوه نگاشت حافظه محلی به گروه های کاری است.
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=-1.2919 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=-1.2212 ... GLOBAL.ID[127]=127 : LOCAL.ID[127]=127 : GROUP.ID[127]=0 : T[127]=-1.2222 GLOBAL.ID[128]=128 : LOCAL.ID[128]=128 : GROUP.ID[128]=0 : T[128]=1.9752 GLOBAL.ID[129]=129 : LOCAL.ID[129]=0 : GROUP.ID[129]=1 : T[129]=1.0197 ... GLOBAL.ID[255]=255 : LOCAL.ID[255]=126 : GROUP.ID[255]=1 : T[255]=1.9462 GLOBAL.ID[256]=256 : LOCAL.ID[256]=127 : GROUP.ID[256]=1 : T[256]=-1.9560 GLOBAL.ID[257]=257 : LOCAL.ID[257]=128 : GROUP.ID[257]=1 : T[257]=-0.9829
CLBufferFree(tangents_handle);
"int iterations){" int iterations=100; CLSetKernelArg(ker,4,iterations);
GLOBAL.ID[262399]=262399 : LOCAL.ID[262399]=255 : GROUP.ID[262399]=1024 : T[262399]=-0.1899
اجازه دهید توضیح دهم که فکر می کنم چه چیزی می تواند در اینجا اتفاق بیفتد:
بیایید دنبالش برویم حتی اگر شکست بخورد
معیار 2: برش زمان اجرا با اندازه گروه
string kernel="__kernel void memtests(__global int* global_id," "__global int* local_id," "__global int* group_id){" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}";
بیایید تا 50 هسته را جک کنیم و زمان بین شروع و پایان تایمر را اندازه گیری کنیم. بدون انجام کار دیگری فقط 50 هسته را روی OpenCL نصب کنید.
سلام.
بنابراین ما برای معیار به چه چیزی نیاز خواهیم داشت؟
- آرایه هسته
- زمان شروع کرنل ها
- زمان پایان کرنل ها
هومممم یه مشکل دیگه هم هست ما میخواهیم «گلوگاه» GPU (یا دستگاه) را پیدا کنیم، اما OpenCL به ما اجازه نمیدهد این کار را انجام دهیم، زیرا خودش بار را کنترل میکند و ما چیزی نمیبینیم، بنابراین، چند هسته میتوانیم ایجاد کنیم؟
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=-0.3564 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=2.3337 ... GLOBAL.ID[255]=255 : LOCAL.ID[255]=255 : GROUP.ID[255]=0 : T[255]=-2.4480 GLOBAL.ID[256]=256 : LOCAL.ID[256]=0 : GROUP.ID[256]=1 : T[256]=2.3620 ... GLOBAL.ID[510]=510 : LOCAL.ID[510]=254 : GROUP.ID[510]=1 : T[510]=-2.2709 GLOBAL.ID[511]=511 : LOCAL.ID[511]=255 : GROUP.ID[511]=1 : T[511]=-0.3056
بیایید 200 مورد را به آن بریزیم
در این مورد باید یک آرگومان در هسته اضافه کنیم، آرگومان را به هسته پیوند داده و مقدار را تنظیم کنیم:
هنوز شکافی وجود ندارد.
به ما اطلاع دهید از حداکثر موارد کاری که یک گروه کاری می تواند داشته باشد، زیرا، این همان کاری است که gpu زمانی که هیچ دستورالعملی ندارد، به تنهایی انجام می دهد؟
اما به قسمت 2 ادامه می یابد
منبع: https://www.mql5.com/en/blogs/post/752650
خوب البته ما می توانیم این همان چیزی است که برای آن است 😅
بار کار را به دو گروه تقسیم کرد!
سپس یک آرایه دوتایی در برنامه خود ایجاد می کنیم و آن را با مقادیر تصادفی در محدوده -2.6 تا 2.6 پر می کنیم.
aa و در انتها بافر رایگان اضافه کنید در غیر این صورت به نظر می رسد که در حال ذخیره (هوشمندانه) مقادیر است
اکنون 50 هسته را انجام دهید
int device_max_work_group_size=CLGetInfoInteger(ctx,CL_DEVICE_MAX_WORK_GROUP_SIZE);
خوب، حالا بیایید تکرارها را به 1000 برگردانیم و آزمایش را با مقادیر مختلف شروع کنیم.
1024 می گوید . 1024 گروه کاری یا 1024 مورد در گروه های کاری در مجموع؟
بیایید 10 میلیون تکرار 100 مورد، که ممکن است برای دقت شناور مشکل ساز باشد؟ اجازه بدید ببینم
کاری که این کار انجام می دهد این است که 3 آرایه حافظه جهانی عدد صحیح global_id , local_id , group_id را دریافت می کند و آنها را با شاخص مربوطه در موقعیت جهانی پر می کند. به عنوان مثال اگر 10 پرتقال در 2 کیسه داشته باشیم، شاخص کیسه را به شاخص آرایه خطی پرتقال ها اختصاص می دهیم.
ما می گوییم، نارنجی[0] در Bag0 و نارنجی است[9] در Bag1 است، ما از شاخص پرتقال در کیسه استفاده نمی کنیم (نارنجی[0] در Bag0 و نارنجی است[4] در Bag1 است) که چیزی در مورد نحوه چیدمان پرتقال ها به ما نمی گوید!
خوب حالا باید یک پرانتز غول پیکر باز کنیم و متأسفانه کار دیگری انجام دهیم.
معیار کنونی از این نظر مشکل دارد که از حافظه زیاد استفاده می کند.
اگر میخواهیم «قطع» هستهها ظاهر شود، باید از «محاسبات» بیشتر از «واکشی» استفاده کنیم.
این تست همچنین زمانی اجرا میشود که بخواهیم دائماً اجرا شود، مشکل دوم ما اگر قطع باشد
نزدیک به راه اندازی مجدد حلقه ما متوجه آن نخواهیم شد!
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=0.7702 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=0.0282 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : T[2]=0.9934 GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : T[3]=2.2652 GLOBAL.ID[4]=4 : LOCAL.ID[4]=4 : GROUP.ID[4]=0 : T[4]=-2.2026 ... GLOBAL.ID[96]=96 : LOCAL.ID[96]=96 : GROUP.ID[96]=0 : T[96]=-1.7437 GLOBAL.ID[97]=97 : LOCAL.ID[97]=97 : GROUP.ID[97]=0 : T[97]=-1.1011 GLOBAL.ID[98]=98 : LOCAL.ID[98]=98 : GROUP.ID[98]=0 : T[98]=0.4125 GLOBAL.ID[99]=99 : LOCAL.ID[99]=99 : GROUP.ID[99]=0 : T[99]=1.8560